

The Commercial Value Of News In The Internet Era – Analysis
By VoxEU.org
The rise of news consumption through social media and the ‘fake news’ phenomenon has raised doubt over the value of original news production. This column uses a comprehensive dataset of French news content produced in 2013 to assess the commercial returns to original news production. It finds that media outlets with a larger fraction of original content do tend to receive greater audiences.
By Julia Cagé, Nicolas Hervé and Marie-Luce Viaud*
The modern media industry is in a state of crisis. While social media seems to swallow the news, many argue that the effectiveness of the media as a check on power is significantly compromised, buffeting Western democracies. Following Brexit and the 2016 US presidential election, the growing importance of ‘fake news’ and the decreasing trust in traditional media have become prominent concerns (Allcott and Gentzkow 2017). According to Boczkowski et al. (2017), young users mainly consume news on social media ‘incidentally’ – rather than engaging with the news content, they no longer differentiate between it and the rest of the social and entertainment information they consume.
Furthermore, not only is the internet era characterised by a new regime of news consumption, but we also observe a new regime of news production. The switch to digital media has indeed affected news production technology. In today’s online world, reproducing competitors’ content has become instantaneous. Is there still a ‘commercial value’ of news in this online world? In a recent working paper, we document the extent of copying online and estimate the returns to originality in online news production (Cagé et al. 2017).
We use a unique dataset covering the entire news content provided online by the universe of French news media during an entire year (2013). Our dataset covers 86 general information media outlets in France: 1 news agency, 59 newspapers (35 local dailies, 7 national dailies, 12 national weeklies, 2 national monthlies, and 3 free newspapers), 10 pure online media (i.e. online-only media outlets), 9 television channels, and 7 radio stations. The news agency is the Agence France Presse (AFP), the third largest news agency in the world (after the Associated Press and Reuters). We track every piece of content these outlets produced online in 2013. Our dataset contains 2.5 million documents.
Using the content produced by news media, we perform a topic detection algorithm to construct the set of news stories. Each document is placed within the most appropriate cluster, i.e. the one that discusses the same event-based story. We obtain a total number of 25,000 stories, comprised of 850,000 documents (about 35 documents per news story). Nearly one third of the news events are about politics, 30% about the economy and less than one quarter about crime, law, and justice. We then study the timeline of each story. In particular, for each story, we determine first the media outlet that breaks the story, and then analyse the propagation of the story, second by second. We investigate the speed of news dissemination and the length of the stories, depending on the topic and other story characteristics.
We show that, on average, news is delivered to readers of different media outlets 172 minutes after having been published first on the website of the news breaker – but in less than 224 seconds in 25% of the cases. The reaction time is shortest when the news breaker is a news agency, and longest when it is a pure online media, most likely because of the need for verification.
High reactivity comes with verbatim copying. We develop a state-of-the-art plagiarism detection algorithm and find that only 32.6% of the online content is original. This finding is illustrated in Figure 1, which plots the distribution of the originality rate. The distribution is bimodal, with one peak for the article with less than 1% original content (nearly 17% of the documents) and one peak for the 100% original articles (nearly 22% of the documents). The median is 14%. In other words, with the exception of the documents that are entirely original, the articles published within events consist mainly of verbatim copying – more than 55% of the articles classified in events have less than 20% originality.
Figure 1 Distribution of the ‘originality rate’ of media content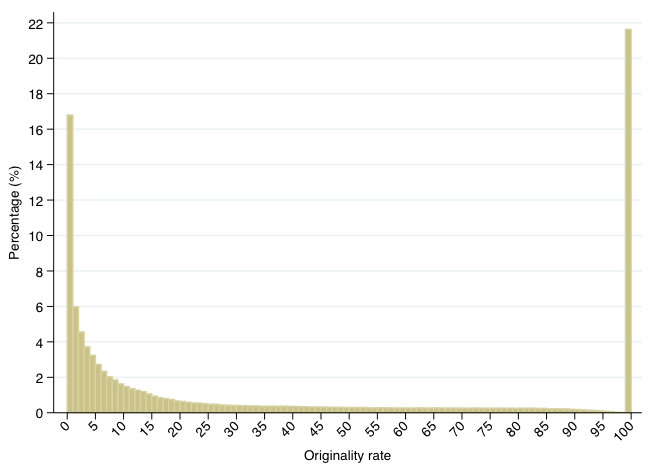
Obviously, copy can take different forms. First of all, we distinguish external (copying from another media outlets) from internal (copying from a previous article you published) copy. Second, we distinguish content copied from the AFP (the news agency) and content copied from other media outlets. All the media outlets that are clients of the AFP are indeed allowed to reproduce the AFP content in its entirety, and the business model of the news agency is based on the reproduction of its content by other media outlets.
But in effect, every time an original piece of content is published on the internet, it is actually published three times – once by the original producer, and twice by media outlets who simply copy-and-paste this original content. (Obviously, in practice, we often observe large numbers of media outlets copying part of the content of an original article. But in terms of numbers of original characters copied, this is equivalent to a situation where each piece of original content is published three times.) Moreover, despite the substantiality of copying, media outlets hardly name the sources they copy. Once we exclude copy from the news agency, we show that only 3.5% of the documents mention competing news organisations they copy as the source of the information, as illustrated in Figure 2.
Figure 2 Share of documents crediting the copied media as a function of the copy rate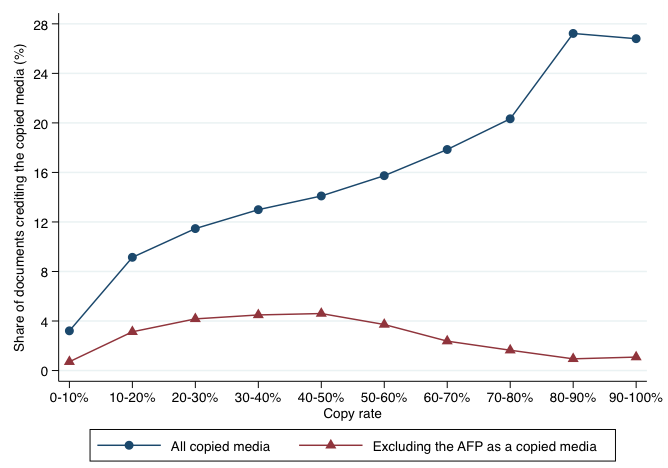
Do original news producers nonetheless benefit from their investment in newsgathering? In instances where the online audience was distributed randomly across the different websites and regardless of the originality of the articles, our results would imply that the original news producer captures only 33% of the audience and of the economic returns to original news production (which, as a first approximation, can be assumed to be proportional to audience, for example via online advertising revenues). However, we show that reputation mechanisms and the behaviour of Internet viewers allow the mitigation of a significant part of this copyright violation problem.
First, using article-level variations (with event, day, and media fixed effects), we show that a 50% increase in the originality rate of an article leads to a 35% increase in the number of times it is shared on Facebook. This finding is illustrated in Figure 3, which plots the estimates of the coefficients from the estimation of the number of times an article is shared on Facebook, as a function of the originality of the article.
Figure 3 Facebook shares and originality rate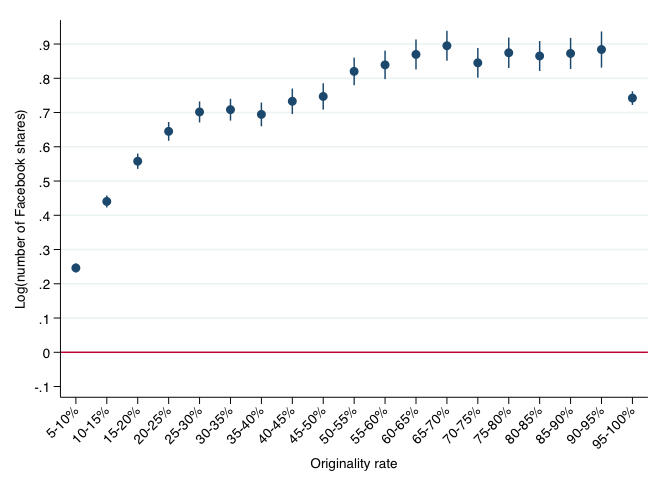
Second, by using media-level daily audience data and article-level Facebook shares, we investigate to which extent readers ‘reward’ originality. To do so, we compute audience-weighted measures of the importance of originality. As a first ‘naïve’ approach, we assume that all the articles published on the website of an outlet on a given day are ‘equally successful’. Doing so, we find that the average audience-weighted original content is above 46%. This reflects the facts that media outlets with a larger fraction of original content tend to receive more audience.
More importantly, if we weight content by media-level audience shares and article-level Facebook shares, we show that the original content represents up to 58% of online news consumption, i.e. much more than its relative production (33%). This means that within a given media outlet, the articles that get more views (as approximated by the number of Facebook shares) are those with more original content. In effect, reputation mechanisms actually appear to solve about 40% of the copyright violation problem, as long as the media outlets realise this and allocate their effort and journalist time accordingly. The observed collapse in the number of journalists in all developed countries (Cagé 2016) may reflect the fact that some outlets have not.
Of course, greater intellectual property protection could also play a role in solving the copyright violation problem and raising the incentives for original news production, and we certainly do not mean to downplay the extent of this problem. Other factors may help rationalise the observed drop in the number of journalists, the decline of advertising revenues, and the increasing use of ad-blockers to begin with (Angelucci and Cagé 2016, Shiller et al. 2017). However, our results suggest that in order to effectively address this issue, it is important to study reputation effects and how viewers react to the newsgathering investment strategies of media outlets.
*About the authors:
Julia Cagé, Assistant Professor in Economics, Sciences Po; CEPR Research Fellow
Nicolas Hervé, Research Engineer, Institut National de l’Audiovisuel
Marie-Luce Viaud, VIF team leader, Institut national audiovisue
References:
Allcott, H, and M Gentzkow (2017), “Social Media and Fake News in the 2016 Election”, Journal of Economic Perspectives, 31 (2).
Angelucci, C, and J Cagé (2016), “Newspapers in Times of Low Advertising Revenues”, CEPR Discussion Paper 11414.
Boczkowski, P, E Mitchelstein, and M Matassi (2017), “Incidental News: How Young People Consume News on Social Media”, Proceedings of the 50th Hawaii International Conference on System Sciences.
Cagé, J (20160, Saving the Media: Capitalism, Crowdfunding, and Democracy, Harvard University Press.
Cagé, J, N Hervé, and M-L Viaud (2017), “The Production of Information in an Online World: Is Copy Right?” CEPR Discussion Paper 12066.
Shiller, B, J Waldfogel, and J Ryan (2017), “Will Ad Blocking Break the Internet?” NBER Working Paper 23058.